Paul S. Scotti1,2*, Atmadeep Banerjee2*,
Jimmie Goode†2, Stepan Shabalin2, Alex Nguyen1, Ethan Cohen3, Aidan J. Dempster4, Nathalie Verlinde1,
Elad Yundler5, David Weisberg1,2, Kenneth A. Norman‡1,
and Tanishq Mathew Abraham‡2,6,7
1Princeton Neuroscience Institute, 2Medical AI Research Center (MedARC),
3Ecole Normale Supérieure, PSL University, 4University of Toronto, 5Hebrew University of Jerusalem,
6EleutherAI, 7Stability AI
(* indicate equal contribution, † indicates core contribution, ‡ indicates joint senior authors)
Announcement📢: We are excited to share MindEye has been accepted to NeurIPS 2023 as a spotlight! An updated camera-ready version of our manuscript is now up on arXiv. See you in New Orleans!
We present MindEye, a novel fMRI-to-image approach to retrieve and reconstruct viewed images from brain activity. Our model comprises two parallel submodules that are specialized for retrieval (using contrastive learning) and reconstruction (using a diffusion prior). MindEye can map fMRI brain activity to any high dimensional multimodal latent space, like CLIP image space, enabling image reconstruction using generative models that accept embeddings from this latent space. We comprehensively compare our approach with other existing methods, using both qualitative side-by-side comparisons and quantitative evaluations, and show that MindEye achieves state-of-the-art performance in both reconstruction and retrieval tasks. In particular, MindEye can retrieve the exact original image even among highly similar candidates indicating that its brain embeddings retain fine-grained image-specific information. This allows us to accurately retrieve images even from large-scale databases like LAION-5B. We demonstrate through ablations that MindEye's performance improvements over previous methods result from specialized submodules for retrieval and reconstruction, improved training techniques, and training models with orders of magnitude more parameters. Furthermore, we show that MindEye can better preserve low-level image features in the reconstructions by using img2img, with outputs from a separate autoencoder.

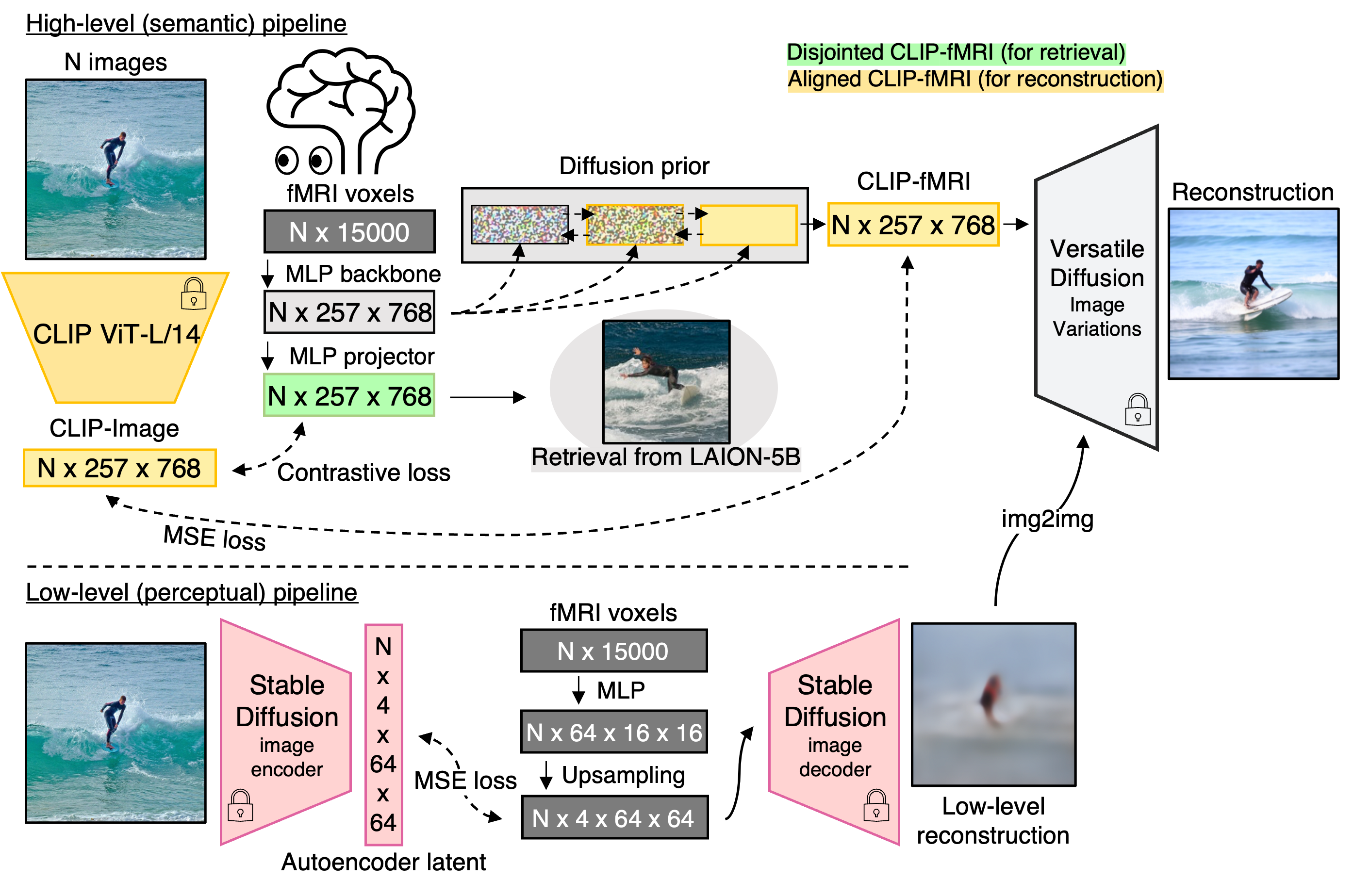
High-Level (Semantic) Pipeline The high-level pipeline is the core of MindEye as it maps voxels to CLIP image space to be fed through pretrained image generation models. The MLP backbone for our high-level pipeline maps flattened voxels to an intermediate space of size 257 × 768, corresponding to the last hidden layer of CLIP ViT/L-14. The backbone consists of a linear layer followed by 4 residual blocks and a final linear projector. The embeddings from the backbone are fed to an MLP projector and a diffusion prior in parallel. The whole model is trained end-to-end with the prior getting an MSE loss and the projector getting a bidirectional CLIP loss. The projector outputs can be used for retrieval tasks and the diffusion prior outputs can be used by generative models to reconstruct images.
Low-Level (Perceptual) Pipeline The low-level pipeline maps voxels to the embedding space of Stable Diffusion’s VAE. The output of this pipeline can be fed to the VAE decoder to produce blurry image reconstructions that lack high-level semantic content but perform well on low-level image metrics. We use img2img to improve our final image reconstructions in terms of low-level metrics, with minimal impairment to high-level metrics, such that we start the diffusion process from the noised encodings of our blurry reconstructions rather than pure noise.
Image/Brain Retrieval Image retrieval evaluations reveal the level of fine-grained image-specific information contained in the predicted brain embeddings. For example, if the model is given a dozen pictures of zebras and the brain sample corresponding to viewing one of those zebras, can the model correctly find the corresponding zebra? If the model can correctly deduce that the brain sample corresponds to an image of a zebra but cannot deduce the specific image amongst various candidates, this would suggest that category-level information but not exemplar-specific information is preserved in the CLIP fMRI embedding. MindEye not only succeeds in this zebra example but also demonstrates 93.2% overall accuracy for Subject 1 in finding the exact original image within the 982 test images.
We can scale up image retrieval using a pool of billions of image candidates. Below, we show results querying the LAION-5B dataset using our CLIP fMRI embeddings. The final layer CLIP ViT-L/14 embeddings for all 5 billion images are available at knn.laion.ai, and can be queried for K-nearest neighbor lookup via the CLIP Retrieval client. For each test sample, we first retrieve 16 candidate images using this method (using a variant of MindEye that maps voxels to the final layer of CLIP). The best image is then selected based on having the highest CLIP embedding cosine similarity to the CLIP fMRI embedding. This image retrieval approach is especially well-suited for tasks involving fine-grained classification, and can be used as an alternative to image reconstruction without a generative model.

fMRI-to-Image Reconstruction The diffusion prior outputs from MindEye are aligned CLIP fMRI embeddings that can be used with any pretrained image generation model that accepts latents from CLIP image space. We evaluated the outputs of MindEye reconstructions across several models including Versatile Diffusion, Stable Diffusion (Image Variations) and Lafite. Here we show results from Versatile Diffusion since it yielded the best results. For each subject, for each test brain sample, we output 16 CLIP image embeddings from MindEye and feed these embeddings through the image variations pipeline of Versatile Diffusion. This produces 16 image reconstructions per brain sample. For our reconstructions we use 20 denoising timesteps with UniPCMultistep noise scheduling and start the denoising process from the noised output of our low-level pipeline (img2img). We then select the best of 16 reconstructions by computing last hidden layer CLIP embeddings and picking the image with the highest cosine similarity to the disjointed CLIP fMRI embedding. We qualitatively compare our reconstructions side-by-side with outputs from other fMRI-to-image reconstruction models below.

Thanks to the MedARC community, including Jeremy Howard, Tommaso Furlanello, Mihir Tripathy, and Cesar Torrico for useful discussion and reviewing the manuscript. Thank you to Furkan Ozcelik, author of Brain-Diffuser, for sharing his code and expert knowledge with our group. We thank LAION for being the initial community where this project developed, and thank Romain Beaumont and Zion English for useful discussion during that time. We thank Stability AI for sharing their high-performance computing workplace and giving us the computational resources necessary to develop MindEye. Thank you to Richard Vencu for help navigating the Stability HPC. Collection of the Natural Scenes Dataset was supported by NSF IIS-1822683 and NSF IIS-1822929. This webpage template was recycled from here.
We show all reconstructions and retrievals for subject 01. The results for the rest of the subjects are present in our GitHub repo

Reconstructions for all 982 images for subject 01

LAION-5B retrievals for all 982 images for subject 01